Prāsa Programming Language
Prāsa is an esoteric programming language that investigates the intersection of technology and cultural identity.
Culture and computing through cultural computing
Telugu is an alphasyllabary writing system with 16 vowels and 36 consonants, and a total of 576 syllable sounds.
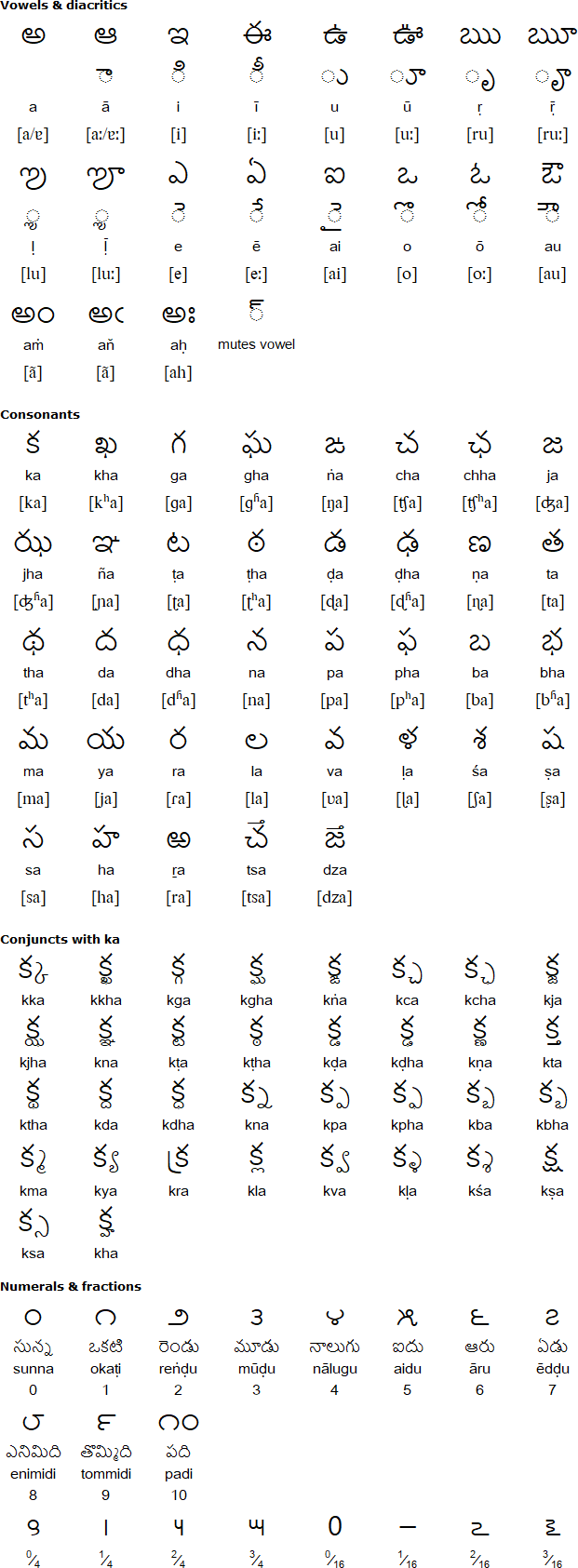
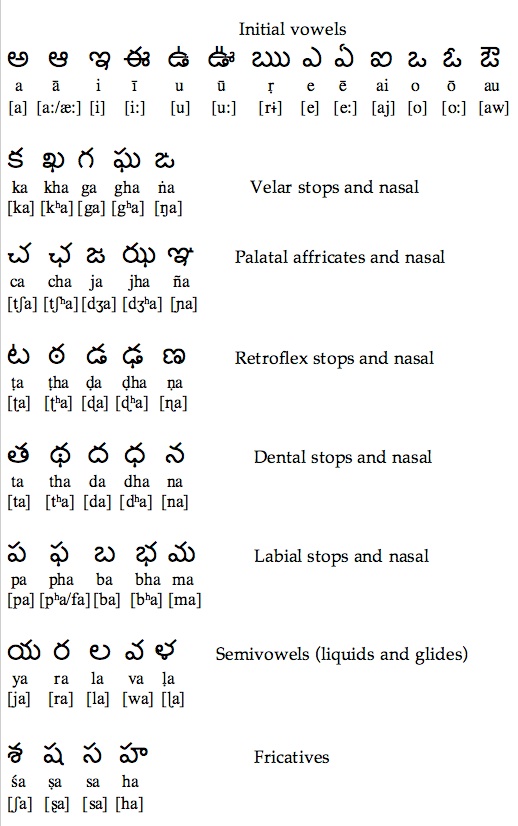
With its expansive glyphs and distinct sounds, poetry in Telugu takes advantage of these systems and relies on rhymes and rhythms that can be performed.
At the same time, the grammar for writing poetry within Chandassu is also quite computational. There’s strict set of rules for writing poetry. Below is an example poem.
నిద్దుర మేలుకొమ్ము తరుణీ! అరుణారుణ రాగ మాలికల్
దిద్దుచునుండె బాలరవి దీప్తులు నీ నునుజెక్కుదోయిపై
ముద్దులు మూటగట్టెను ప్రముగ్ధ పయోరుహ పత్రనేత్ర!నీ
నిద్దపు నీలిముంగురులు నెన్నుదుటన్ నటనమ్మొనర్చుచున్
This is a poem that falls within the Vrutta Padyalu form, a category for 4 subforms with similar prose structure.
- A poem in this form is traditionally 4 lines long (padyam)
- Each line must have exactly 20 syllables only (ganam)
- Second letter in every line needs to be the same across all (prasa)
- First and tenth letter in each line should be a sound from the same consonant (yati)
- Each line should match exactly with the following syllable sequence (gana vibhajana) - U I I U I U I I I U I I U I I U I U I U
Translating poetic grammar as a programming language
1. Form
Prāsa’s movement is inspired by the Turing Tape, where the head can go from one cell to another. But unlike the TM, Prāsa’s tape only exists in the positive space. Cells start from 0 and can only move forward. Any new line that starts with an indentation indicates movement. Each level of indentation moves the cell that many cells forward.
This has been a key point within the process of building this language, as it connects the line from the technical function of the language to its form. Cell-based approach allows for a clear, yet strict set of rules to exist for this language, while leaving the space for creative freedom untouched.
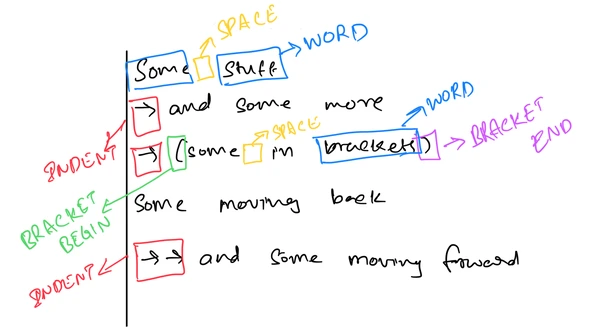
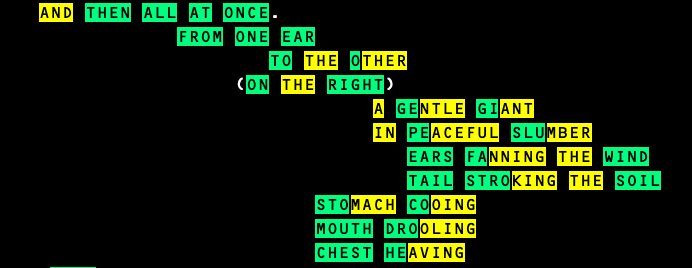
Programs need not be linear, from left-to-right, top-to-bottom. Programs have the flexibility to start from the end of the cell and work its way backwards, or start from the center, move forward and come back again, or oscillate between the cells to play with the form of the program itself. Each empty space in Prāsa adds function. Meaning exists where words don’t.

Excerpt from the HELLO, WORLD! program by Janani Venkateswaran
2. Grammar
In Prāsa, and in Telugu, syllables form the most foundational component. There’s long syllables, and short syllables
- Long syllable = U = guruvu
- Short syllable = I = lahugvu
Then there are sets of gana. A set of 3 (sometimes 2) possible syllable sequences form a set. Short-long-short is the ja-ganam. Below are a list of all sets
| sequences | name | symbols |
| guruvu-laghuvu-laghuvu | bha-ganam | U I I |
| laghuvu-guruvu-laghuvu | ja-ganam | I U I |
| laghuvu-laghuvu-guruvu | sa-ganam | I I I |
| laghuvu-guruvu-guruvu | ya-ganam | I U U |
| guruvu-laghuvu-guruvu | ra-ganam | U I U |
| guruvu-guruvu-laghuvu | ta-ganam | U U I |
| guruvu-guruvu-guruvu | ma-ganam | U U U |
| laghuvu-laghuvu-laghuvu | na-ganam | I I I |
Utpalamāla, Campakamāla, Mattēbham, and Śārdūlam are the four key forms of poetry within a category of poems called Vrutta Padyam. Prāsa uses these four grammatical forms within its implementation.
Utpalamāla
UII UIU III UII UII UIU IULength: 20
Campakamāla
III IUI UII IUI IUI IUI UIULength: 21
Mattēbham
IIU UII UIU III UUU IUU IULength: 20
Sārdūlam
UUU IIU IUI IIU UUI UUI ULength: 19
To write a valid program in Prāsa, we are but forced to do the computation ourselves - an act of taking the agency back from the computer.
3. Outputs
Each cell value’s corresponding ASCII character is the output print.
Summing
With the Telugu Chandassu syllablic grammar implemented with the cell-based approach, computational values automatically fell into place. Number of syllables in a cell is the value of that cell. And since cells are defined by their indentations, two lines on the same level of indentation can be attributed to the same corresponding cell.
Scaling
Alphabets on the ASCII table do not start until 65. To make it easier to reach 65, while adding another level of complexity, Prāsa allows for multiplications in a cell. The intentions of this language have always been to stay as close to natural language as possible, and avoid any symbols that are characters that do not fit into standard written language. Parenthesis is a common-ground. They’re quite common in writing, and they can also bring in another layer of function to the language. If a cell starts with (, the number of syllables between the opening and closing parenthesis are multiplied to the original value of the cell. And if a cell
doesn’t exist, then they are multiplied by 0. And so, all cells start with an initial value of 0. Since the Chandassu syllable length for any form of poem does not exceed 21, I’ve taken the creative freedom to push the number of syllables that can exist in a cell. As long as a consequent part of each cell matches with the pattern, it is valid. This also allows for more freedom into writing a program that can print out a value.
4. Language
The current implementation of Prāsa is built on an approximation of the CMU English dictionary. Syllables in English do not follow a long-short pattern, but rather build on syllable stress. Primary stress syllables, or secondary/no stress syllables. Although they do not quite translate accurately, I have taken the creative freedom during this process to map them to their counterparts.
Most dictionary datasets I could find also do not provide the stress pattern. The CMU dictionary comes closest with an IPA translation for each word in the dictionary. However, to make the code-writing experience more intuitive, and to allow for an expansive approach, I have created an approximation of the dictionary that can split a word into each of its syllables, along with their syllable stress notation.

Python code to estimate the syllable sounds in the dictionary. Text version of the code can
accessed here
The syllables are only an approximation and have not been tested thoroughly.
But since the project relies on a dictionary format I have built, this also allows for extending the language into working with any language with its dictionary in the same structure.
RIVER:
{
"sc": 2,
"sp": "UI",
"seg": [
{
"syllable": "RI",
"position": 1,
"pattern": "U"
},
{
"syllable": "VER",
"position": 2,
"pattern": "I"
}
]
}| key | desc |
|---|---|
| sc | syllable count |
| sp | syllable pattern |
| seg | syllable-based segments |
| seg.syllable | syllable part |
| seg.position | position of the syllable in the word |
| seg.pattern | U / I pattern for the syllable segment |
Compiling it all
The interpreter is built in JavaScript, and is a recursive function that
takes in a string of Prāsa code, and returns the output. The function
iterates through each character in the string, and proceses it through the lexer, parser and evaluator functions.
The lexer looks for the following tokens in the input text.
| type | value | line |
|---|---|---|
| INDENT | 0 | 0 |
| WORD | from | 0 |
| WORD | the | 0 |
| WORD | river | 0 |
| INDENT | 1 | 1 |
| WORD | to | 1 |
| WORD | the | 1 |
| WORD | sea | 1 |
| INDENT | 0 | 2 |
| BRACKET_BEGIN | 2 | |
| WORD | will | 2 |
| WORD | be | 2 |
| WORD | free | 2 |
| BRACKET_END | 2 |
A full documentation is available at prasa.software
Earlier prototypes of the implementation relied on the phonemes from the CMU Pronuncing Dictionary, with a higher accuracy of the syllable approximation than the current implementation. The language was also workshopped with a small group of participants at the Creative Computing Institute to gather feedback. Most of the feedback was about the experience with the editor, and not necessarily the language itself. The writing experience felt unintuitive, and forcing an unavoidable cross-checking with the reference page. With the subsequent version, I have implemented a debug panel, to mimic a traditional code editor. While all the necessary components were there, figuring out the syllable sequences for the input code still seemed to be lacking. Building upon the next round of feedback, the decision to rewrite the dictionary to approximate the syllable parts of every word was implemented. This supports an immediate feedback on the editor, with a space for dispalying errors in words with no additional clicks.
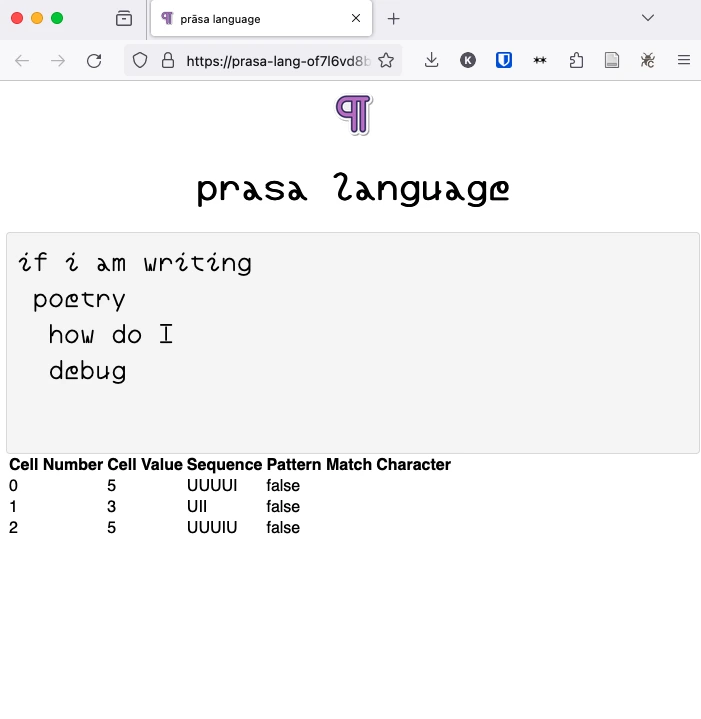
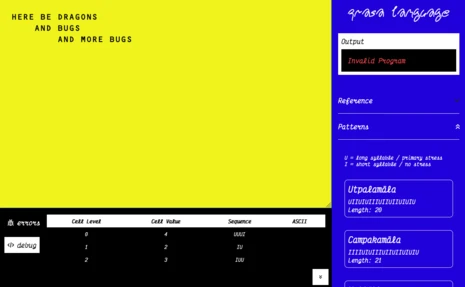
Earlier versions of the editor.
The current implementation of the editor can be found at prasa.software/write